
KubeBlocks for
Kafka
Apache Kafka is a distributed event streaming platform capable of handling trillions of events per day. It provides high-throughput, fault-tolerant, real-time data pipelines for event-driven architectures, log aggregation, and stream processing.
Supported versions
Available on
 AWS
AWS Azure
Azure GCP
GCP OCI
OCI Alibaba Cloud
Alibaba Cloud Rancher
Rancher OpenShift
OpenShiftDatabases
 MySQL
MySQL PostgreSQLOracle
PostgreSQLOracle SQL Server
SQL Server Redis
Redis MongoDB
MongoDB ClickHouse
ClickHouseVector & AI
 Qdrant
Qdrant Milvus
Milvus Elasticsearch
ElasticsearchMessage queues
 RocketMQ
RocketMQ RabbitMQ
RabbitMQ Kafka
KafkaOthers
 VictoriaMetrics
VictoriaMetrics InfluxDB
InfluxDB etcd
etcd ZooKeeper
ZooKeeperExtend database engines like plug-ins
KubeBlocks provides unified database operations through its addon-based architecture. With KubeBlocks Enterprise, access over 15 seamless integrations to scale your database services.
One control plane, consistent operations across all engines — powered by the addon mechanism.
Run Kafka with guided lifecycle, scaling, tuning, and data workflows
Launch, scale, tune, protect, observe, control access, audit, and manage Kafka topics from KubeBlocks Enterprise workflows backed by real console evidence.
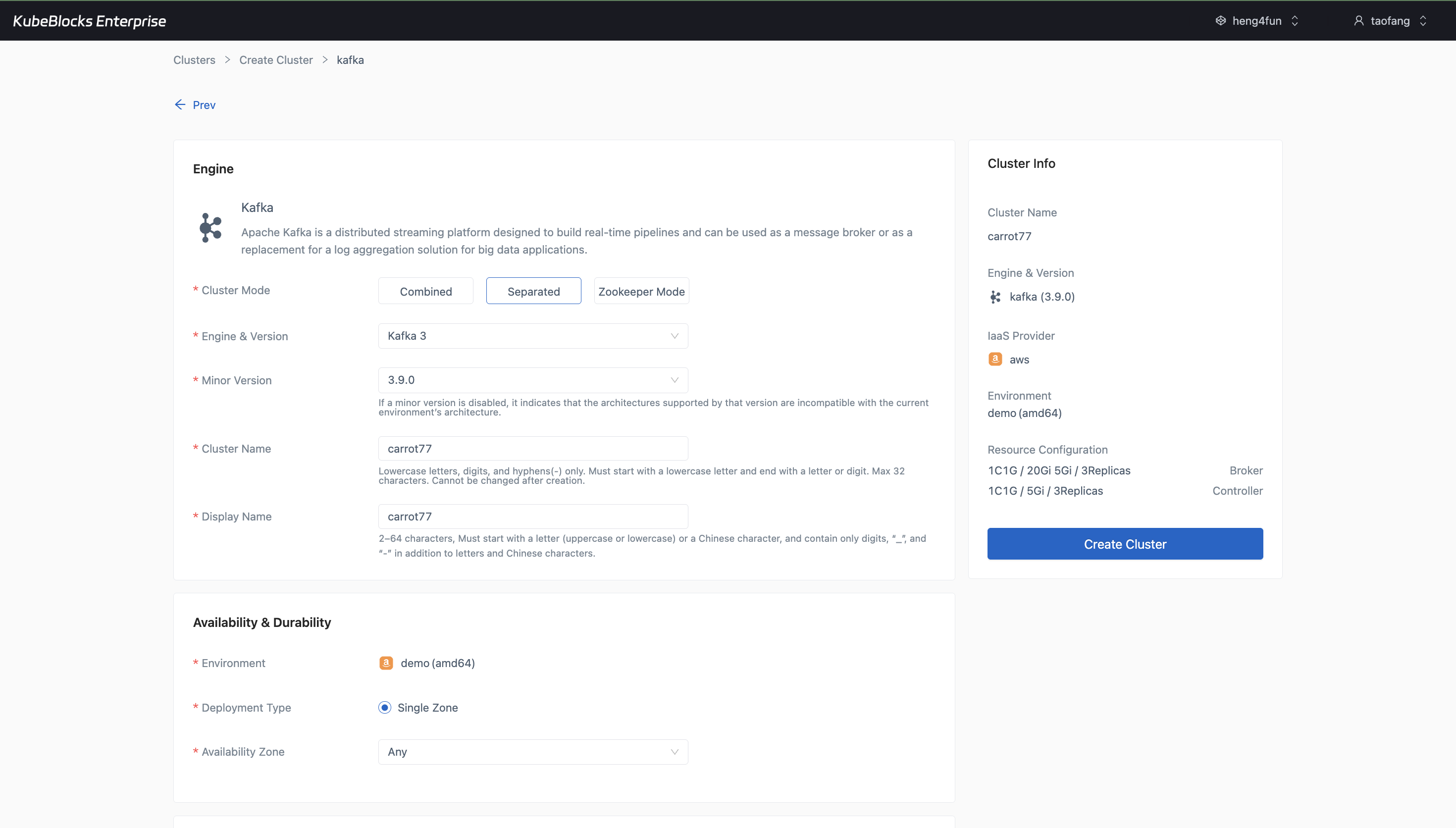
The create wizard makes Kafka mode, version, Broker and Controller settings, replica counts, storage, and backup choices easy to review before provisioning.
Launch Kafka from a create wizard that shows real cluster choices
Create Kafka from a wizard that makes cluster mode, engine version, broker and controller roles, replica counts, compute profiles, storage settings, backup policy, and project placement visible before provisioning starts.
- Use the Separated Kafka 3.9.0 wizard to surface distinct Broker and Controller configuration in one workflow.
- Review replica counts, CPU and memory choices, data storage, metadata storage, backup settings, and network-related options before submission.
- Keep the creation story focused on the configuration surface that users validate before the cluster is provisioned.
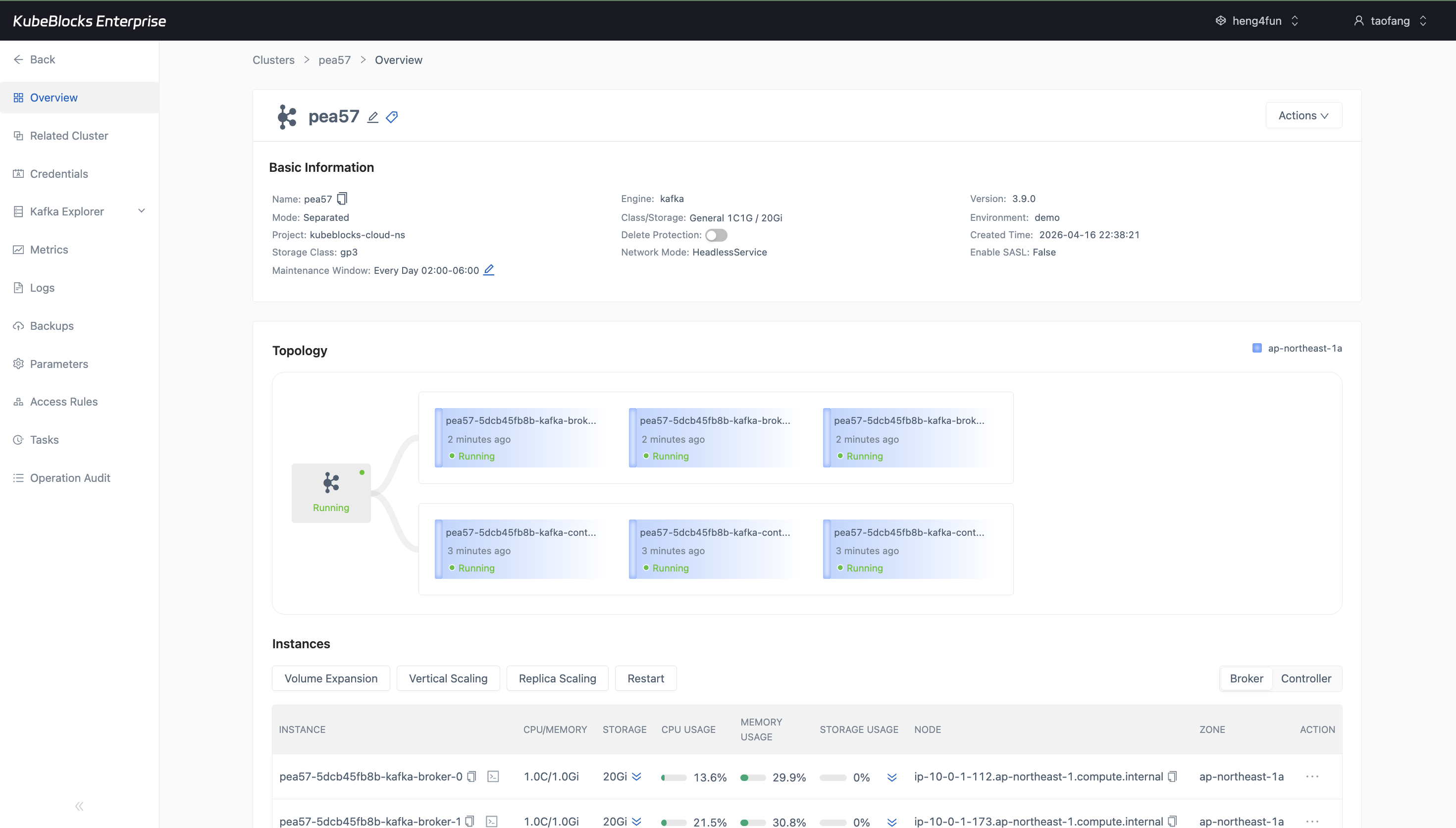
The overview keeps Kafka high-availability evidence visible with a six-node topology that separates broker and controller roles.
Show Kafka topology with multiple running brokers and controllers
Use the overview topology to verify a multi-replica Kafka deployment with separate broker and controller roles so teams can confirm the cluster shape before routing application traffic.
- Validate a Separated Kafka deployment with three running brokers and three running controllers from one topology view.
- Confirm role distribution, zone placement, and per-node Running status before handing the cluster to application teams.
- The tested console did not surface a separate leader transfer or rebalance action, so topology evidence is used as the current high-availability proof point.
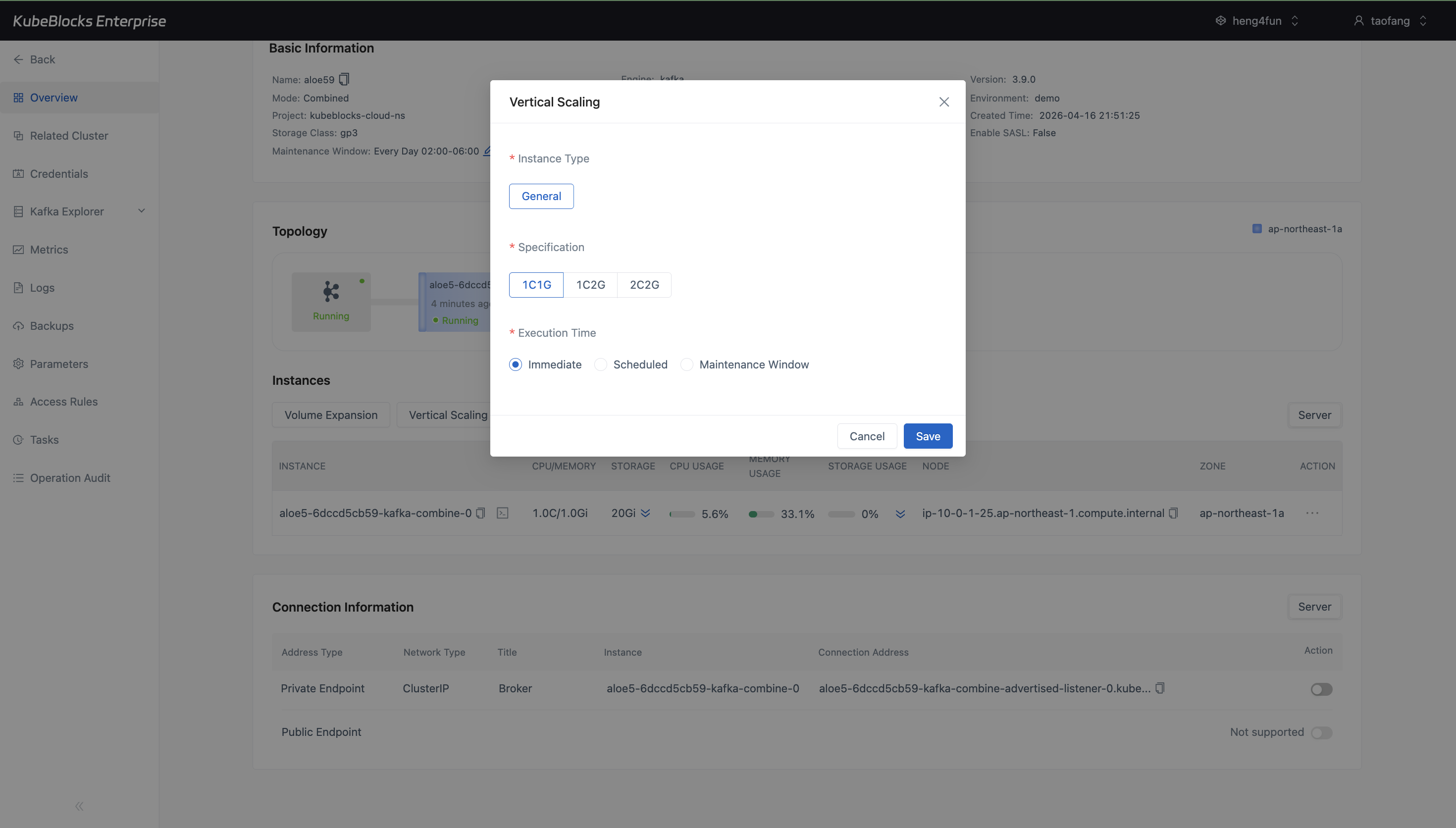
Vertical Scaling shows Kafka CPU and memory choices plus execution timing before the operation is submitted.
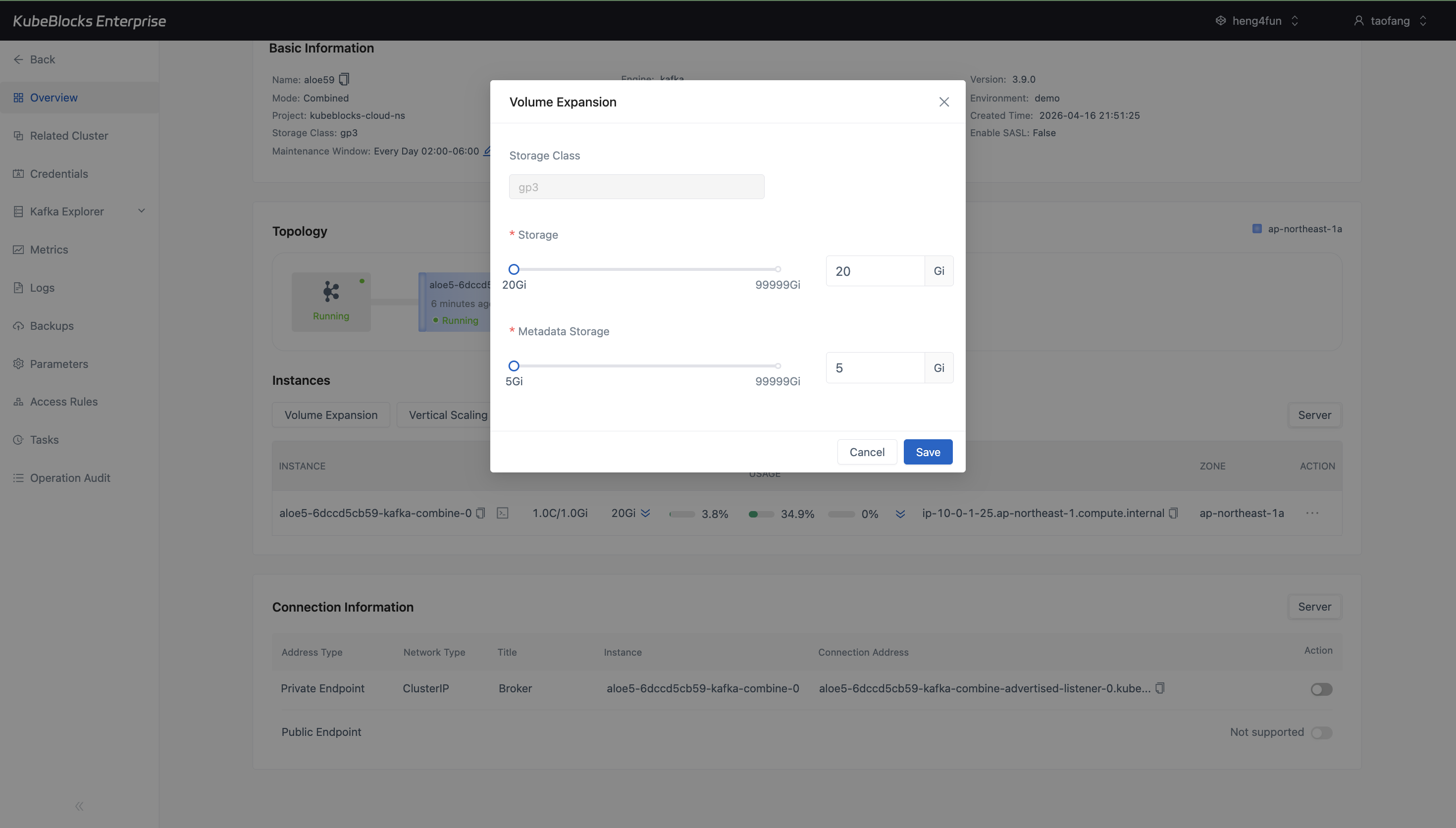
Volume Expansion makes data storage and metadata storage capacity controls explicit before users grow Kafka disks.
Adjust Kafka compute and storage from dedicated dialogs
Scale Kafka capacity through option-driven dialogs that show the available CPU, memory, and storage targets before users submit a change.
- Use Vertical Scaling to choose the next Kafka CPU and memory profile without editing infrastructure objects by hand.
- Use Volume Expansion to review current data and metadata storage sizes and enter the target capacity.
- Keep capacity planning focused on choices and limits instead of relying on overview task status as proof of capability.
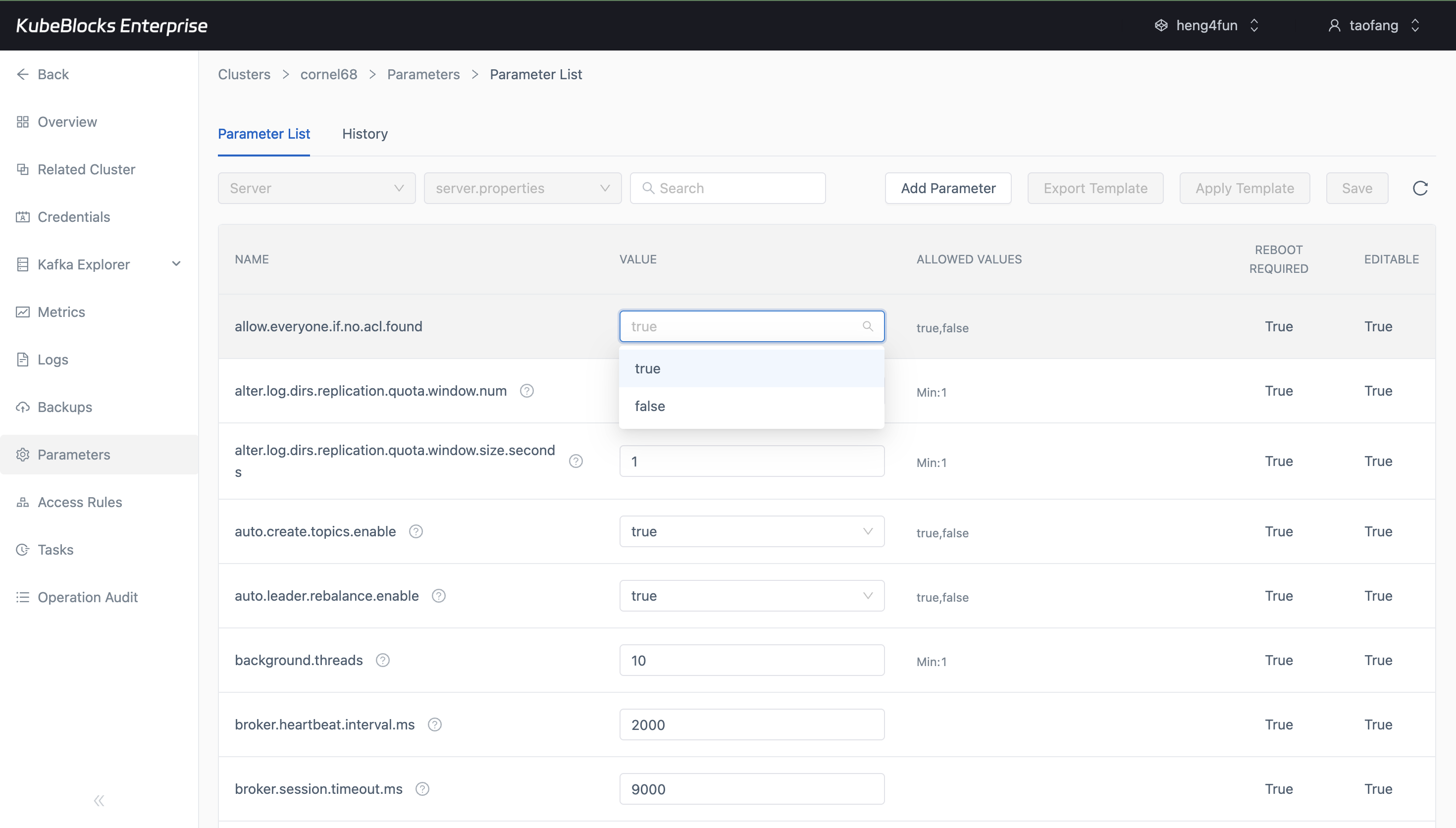
The Parameters workspace gives users a focused place to review and tune Kafka runtime configuration.
Tune Kafka parameters from the Parameters workspace
Review Kafka runtime settings in the Parameters workspace, separate configuration changes from scaling actions, and apply tuning through the same console surface used for day-2 operations.
- Inspect Kafka configuration values from a dedicated parameter list instead of searching through raw manifests.
- Prepare retention, throughput, and broker behavior updates from a focused tuning workspace.
- Keep parameter changes distinct from lifecycle, scaling, and backup workflows for safer review.
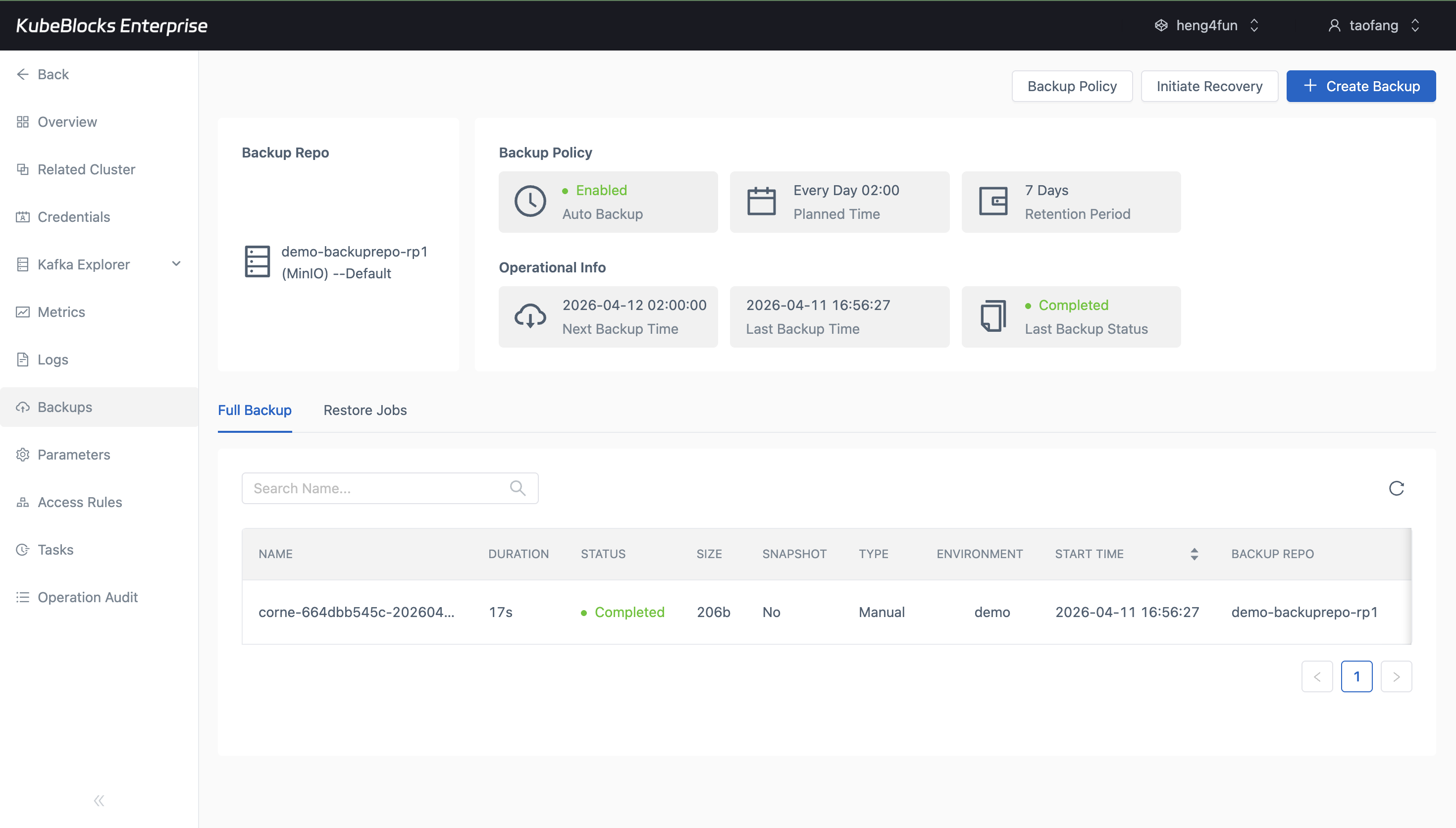
Backup history helps teams confirm Kafka protection points before risky changes or recovery drills.
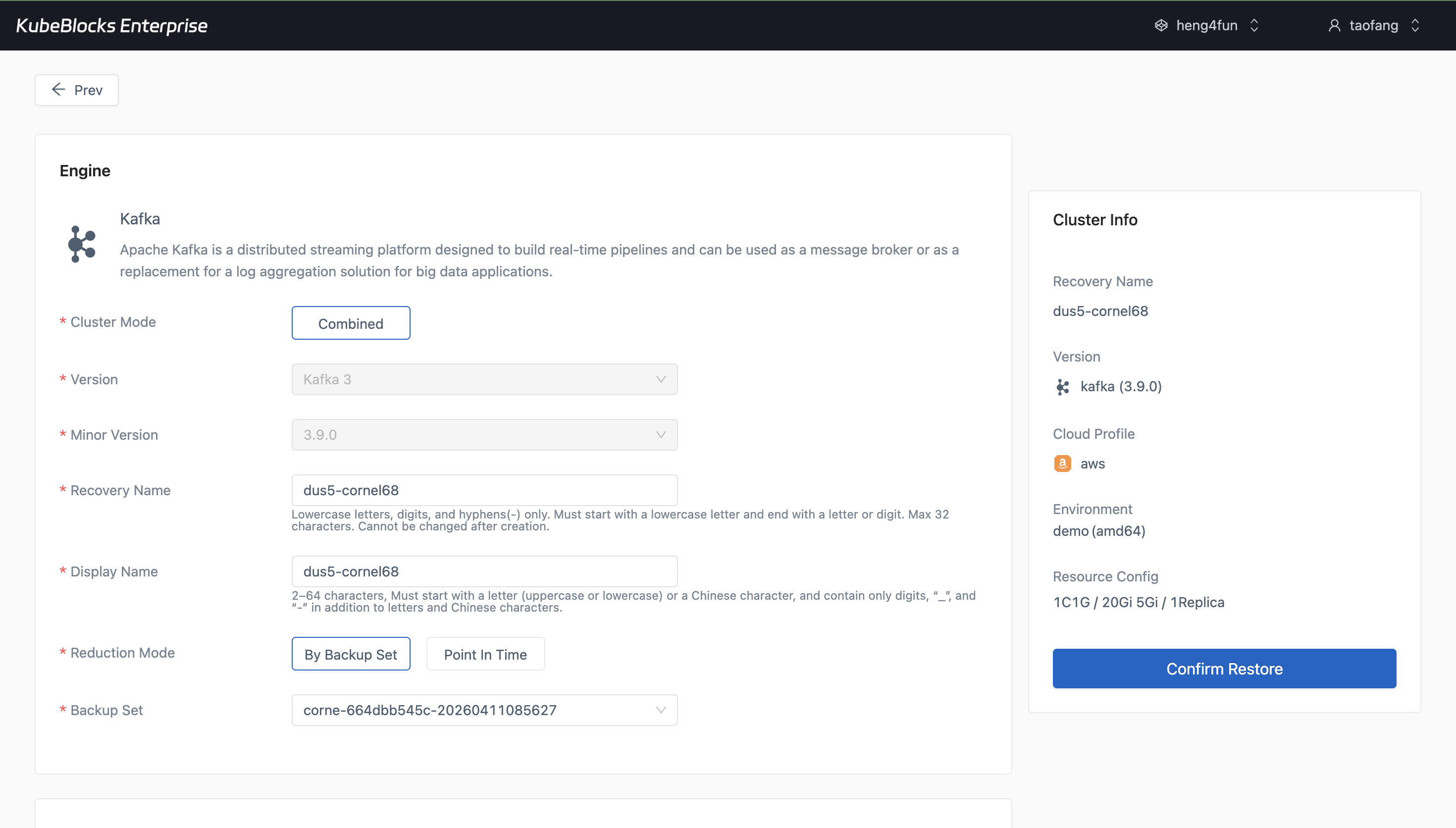
The restore wizard turns existing Kafka backups into a guided path for validation and recovery planning.
Protect Kafka data with backup and restore workflows
Create Kafka backups, review backup history, and open restore workflows from existing backup sets when teams need recovery validation or pre-change protection points.
- Review full backup records with repository, status, and timing visible in the Backups workspace.
- Launch restore from an existing backup set to validate recovery planning before production incidents.
- Keep data protection workflows separate from daily lifecycle and scaling actions.
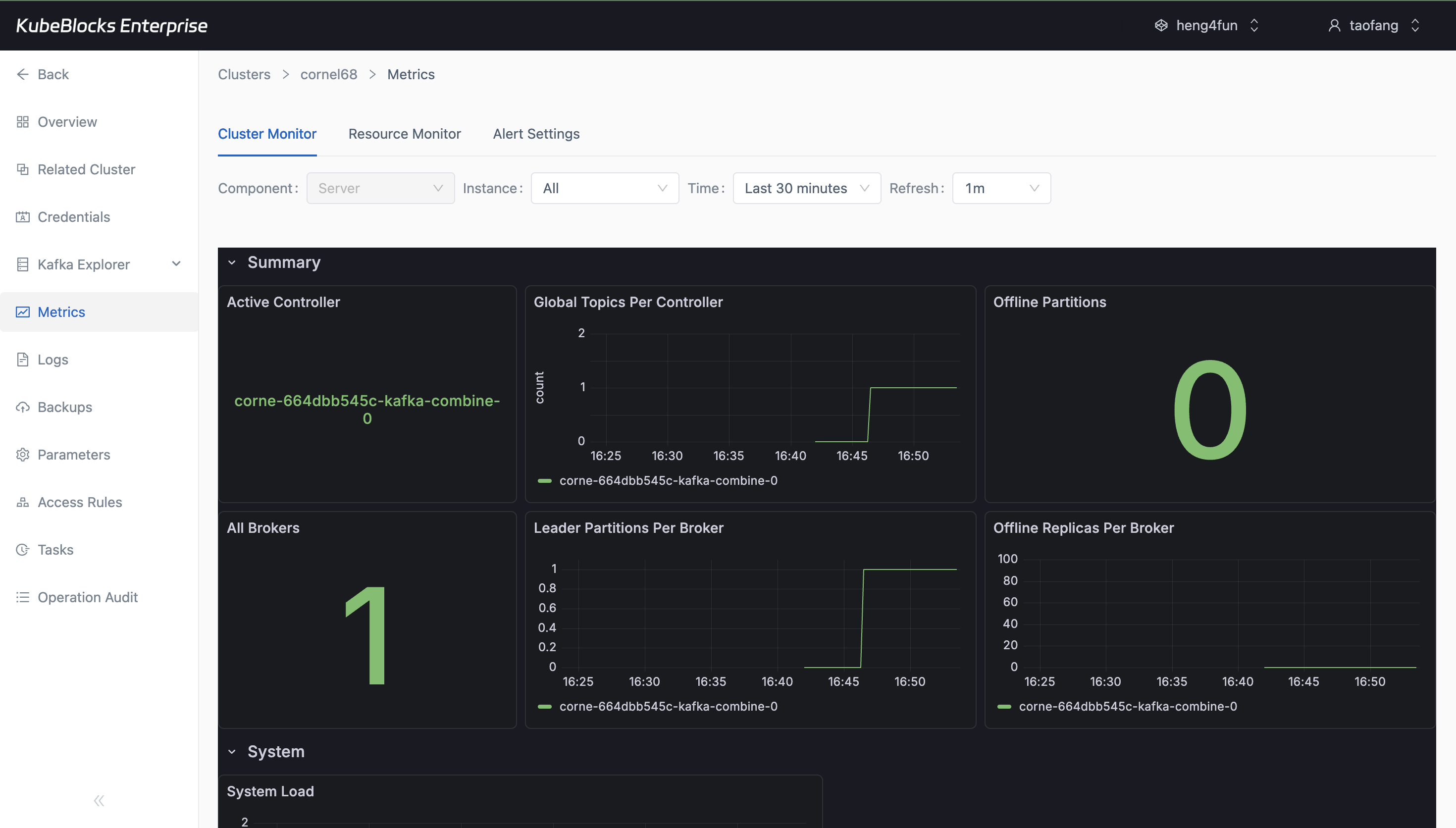
Metrics give users a live view into Kafka health after monitoring data is hydrated.
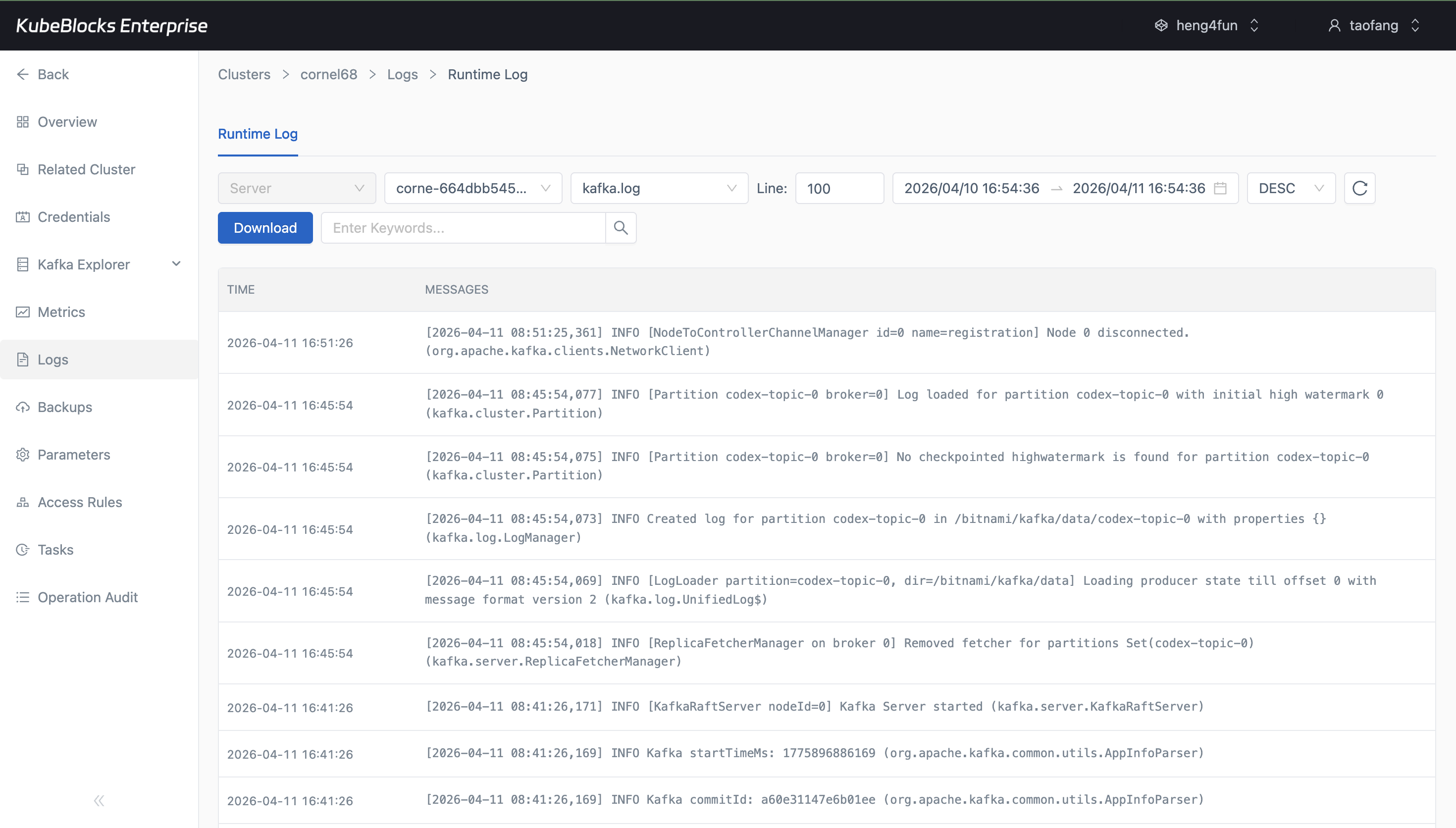
Runtime logs capture Kafka activity for faster validation and troubleshooting.
Watch Kafka health with metrics and runtime logs
Monitor Kafka resource usage and service health from Cluster Monitor, then pivot into Runtime Log when teams need broker-level troubleshooting evidence.
- Use Cluster Monitor charts to review Kafka health after the monitoring panels finish loading.
- Inspect Runtime Log for broker startup, topic activity, and troubleshooting details.
- Keep live health signals and log evidence close to the cluster operations workspace.
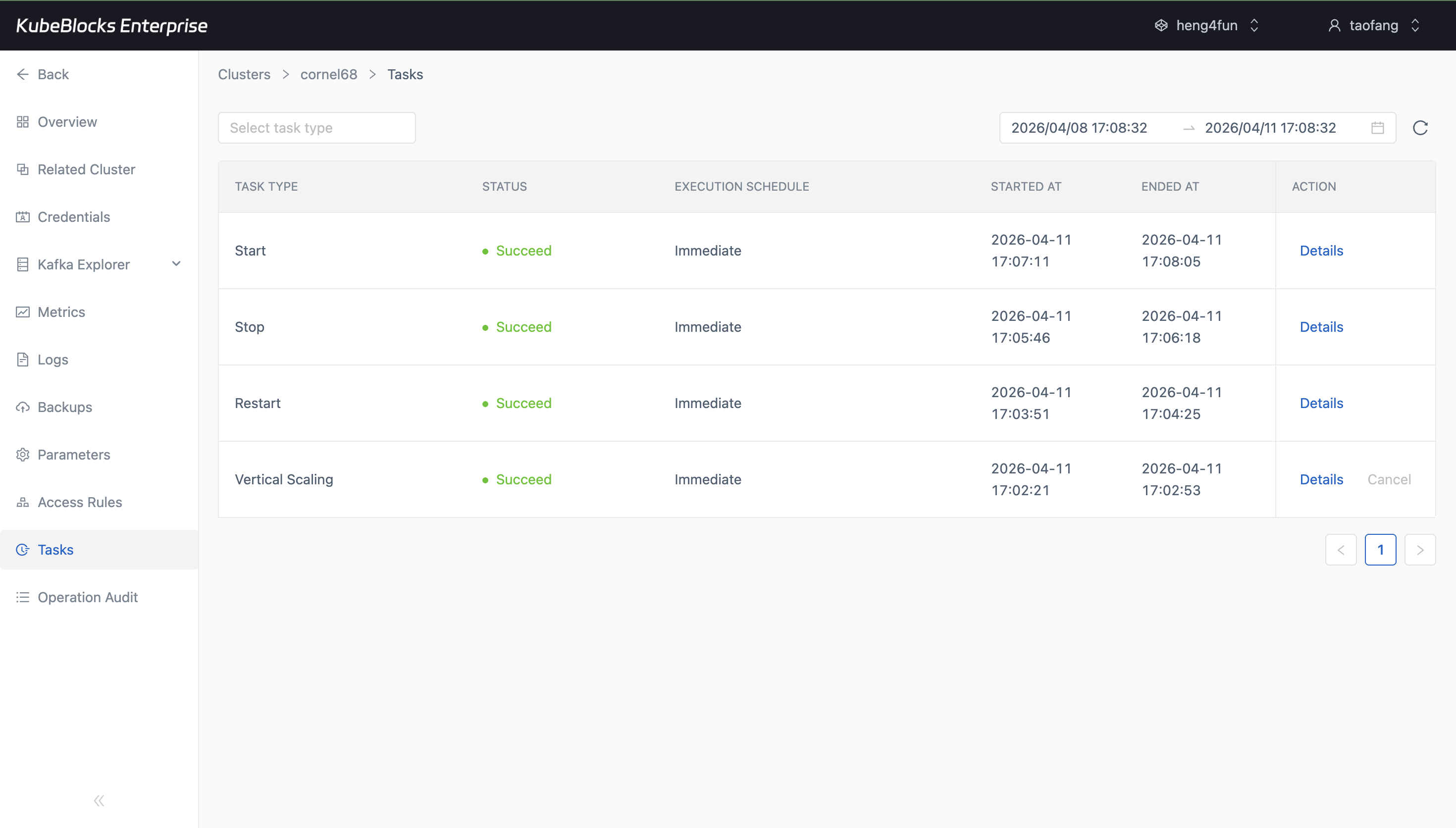
Task history provides a reviewable timeline for Kafka operational changes.
Trace Kafka operations from task history
Use task records to review operational changes such as creation, backup, restore, scaling, and lifecycle activity so teams can understand what changed and when.
- Review task type, status, execution schedule, start time, and end time from one task timeline.
- Confirm day-2 operations finish successfully before handing the cluster back to application teams.
- Use task history as evidence for change review, runbook validation, and operational handoff.
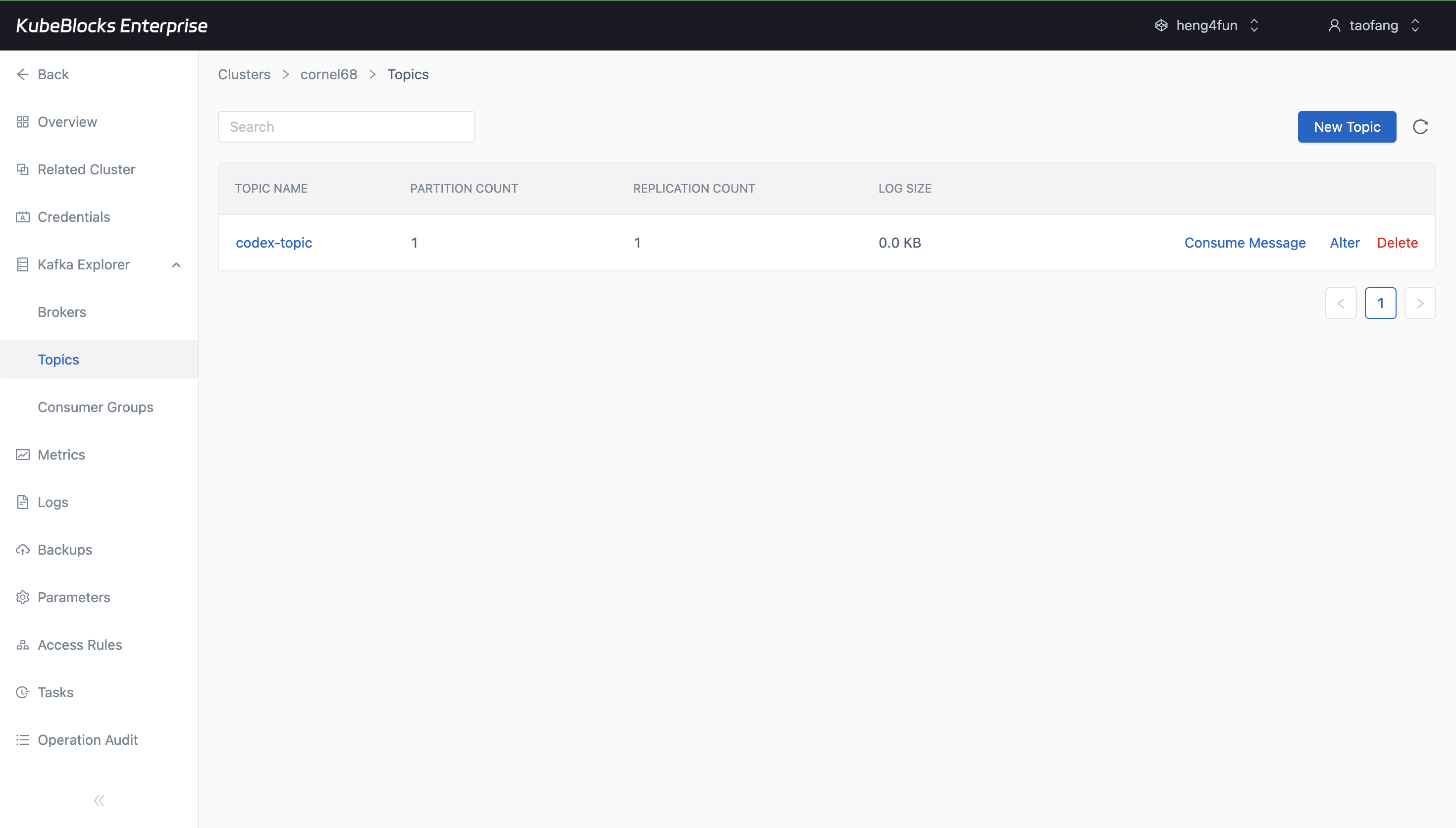
Topic creation gives teams a fast way to prepare Kafka namespaces for new event flows.
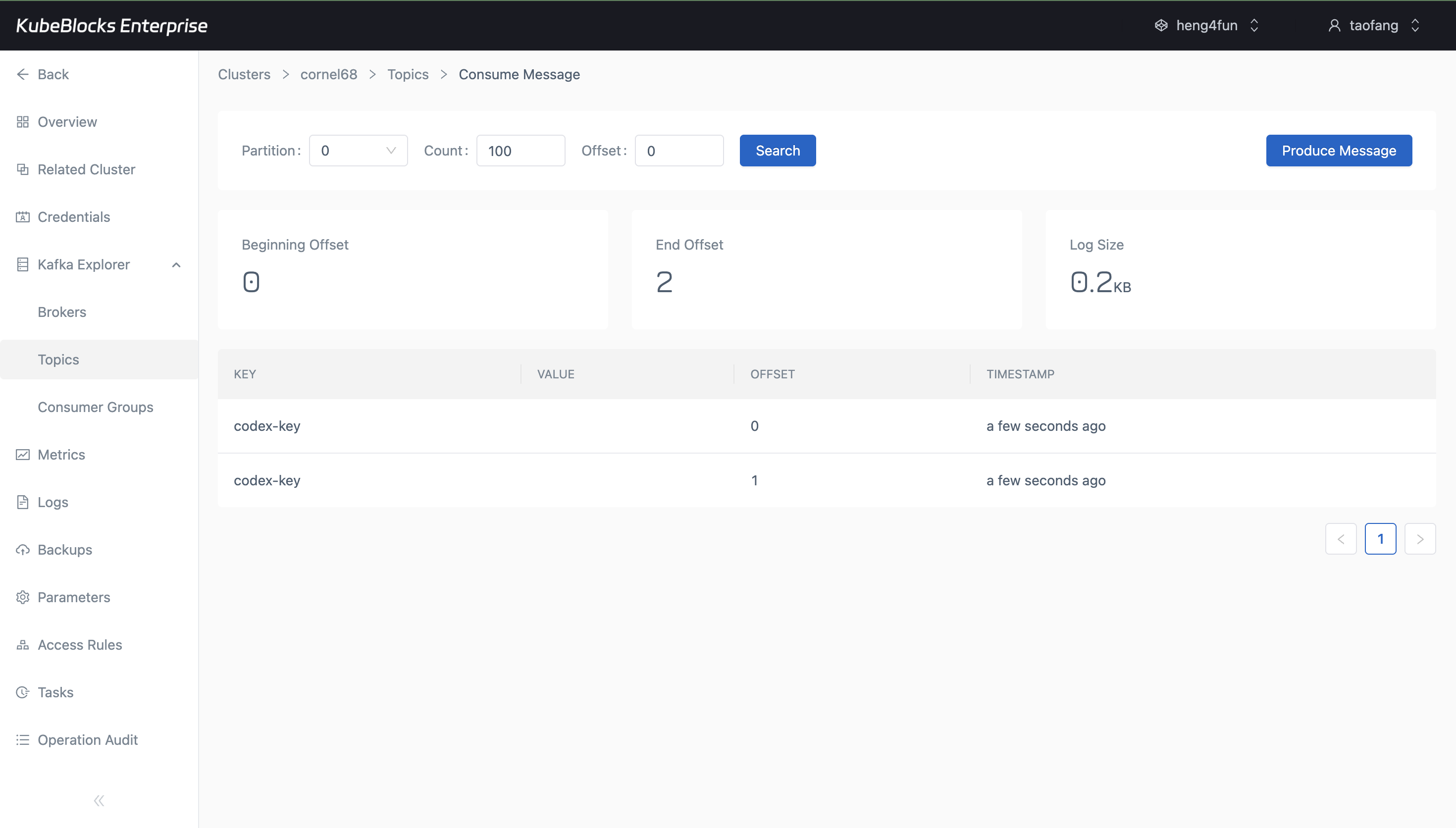
Built-in produce and consume views help teams confirm Kafka traffic before applications connect.
Create topics and validate message flow from Kafka Explorer
Manage Kafka topics and validate publish-consume behavior from built-in console views before application teams connect their producers and consumers.
- Create Kafka topics from Kafka Explorer and confirm they appear in the topic list.
- Produce and consume test messages to validate topic readiness and message flow.
- Use the tested console evidence to document the current account and ACL management behavior separately from topic operations.
Want full Day-2 operations on Kubernetes? Supported by KubeBlocks Kafka Kubernetes Operator →
Ready to build your own DBaaS on Kubernetes?
Talk to our team and see how KubeBlocks Enterprise can help you consolidate databases, strengthen security, and reduce operational costs.